
Daoud Chami, Innovation Solution Manager bij Positive Thinking Company over Data & Analytics-expertise, stelt vragen over de evolutie van het beroep van Data Scientist.
Dit artikel is gebaseerd op een lezing van Daoud, ‘Where is Data Science going?’, gegeven tijdens een Meetup with Lyon Data Science en Devoxx 2023. Het doel van het artikel is een antwoord geven op de vraag: “Wat is de toekomst van het beroep Data Scientist?”
Klanten willen vandaag de dag infrastructuren zelf ontwerpen en niet alleen uitsluitend werken met POC’s, dit kan dankzij platformen en infrastructuren die een deel van devOps kunnen beheren, van productie tot model lifecycle management. Aan de andere kant horen we ook veel over een nieuwe term: Machine learning engineering.
In het licht van deze veranderingen, hoe zal de Data Scientists zich moeten positioneren op de Data value chain?
Om hier een concreet antwoord voor te formuleren, bespreekt Daoud de basisprincipes van de Data Scientist, de reikwijdte van de expertise over verschillende Data beroepen heen en de toekomstige mogelijkheden van deze beroepsfunctie.
Wat onderscheidt Data Scientists van andere Data beroepen?
De Data Scientist is degene die, uitgaande van data, een model ontwikkelt en daarbij zakelijke vaardigheden gebruikt.
Een model is een algoritme waarvan het gedrag afhangt van parameters die tijdens de trainingsfase op een grote gegevensset kunnen worden geschat, om op deze manier voorspellingen te produceren die zo getrouw mogelijk zijn aan de verwachte eindresultaten. In principe draait het rond het voorspellen van een gebeurtenis.
De Data Scientist is degene die het model ontwerpt of degene die de code schrijft die het model produceert. Natuurlijk doet de Data Scientist dat niet alleen, maar dit is wat hem onderscheidt van andere functies die te maken hebben met Data. Hier ligt zijn kernvaardigheid en toegevoegde waarde. Bijvoorbeeld, met een dataset die uit meerdere variabelen bestaat om vastgoed te beschrijven, kan de opgave voor de datawetenschapper zijn om de prijs te voorspellen op basis van bepaalde set variabelen. Om op deze manier de vraag te beantwoorden: “Zijn we in staat om de prijs van een woning te voorspellen op basis van de beschrijvingsgegevens?”
De basisassumptie is dat er correlaties zijn tussen de variabelen en de vraagprijs. De Data Scientist zal bijgevolg de verbanden tussen elke variabele en de prijs van het vastgoed controleren. Verder zal hij ook feature engineering uitvoeren: om informatie te combineren en een nieuw resultaat te creëren. Tot slot controleert hij of deze laatste informatie ook aanleiding geeft tot actie. Hiervoor is natuurlijk zakelijke kennis van de betreffende sector nodig.
Verschil Data Scientist en Data Analist
De taak van de Data Scientist is om informatie die nodig is om te leren en voorspellingen te doen, te verzamelen én informatie te creëren als die nog niet beschikbaar is. Door zakelijke en wiskundige kennis te gebruiken, kan hij een model voorstellen dat verderop in het proces in productie moet worden genomen. Om dit te bereiken, zal de Data Scientist probabilities gebruiken om zijn voorspelling te ondersteunen.
Hier zien we al een groot verschil met een gewone Data Analist, die in plaats daarvan statistieken zal mobiliseren om eindresultaten te behalen.
De Data Scientist zal zich voornamelijk bezighouden met de volgende keten:
- Het opschonen van gegevens
- Het extraheren of creëren van relevante kenmerken
- Het trainen van een model
- Evaluatie van het model
Deze cyclus is iteratief en kan zo vaak als nodig worden herhaald tot een model is ontstaan dat voldoende kan voorspellen wat men probeert te beschrijven. Een Data Scientist doet echter meer dan dat: zo zijn velen bedreven in het uitvoeren van gegevensanalyses en in het gebruik van Tableau, Power BI… Er zijn ook Data Scientists die goed zijn in data engineering: gegevens voorbereiden, formatteren en zo optimaal mogelijk opslaan op gedistribueerde systemen.
Machine learning is dan ook de vaardigheid die Data Scientists onderscheidt van gewone Data Analisten, maar het karakteriseert hem niet compleet. De Data Scientist doet aan machine learning en soms aan Data Analysis en Data Engineering. Soms implementeert en beheert hij ook de CI/CD, om de levenscyclus van machine learning-producten aan te passen aan complexere systemen, maar ook aan meer basale systemen. Dit houdt ook rigoureus testen en configureren in, maar onze Data Scientist moet polyvalent zijn. Het komt echter zelden voor dat iemand al deze factoren beheerst en bijgevolg alles zelf doet.
Wat is de reikwijdte van de Data Scientist en andere Data beroepen?
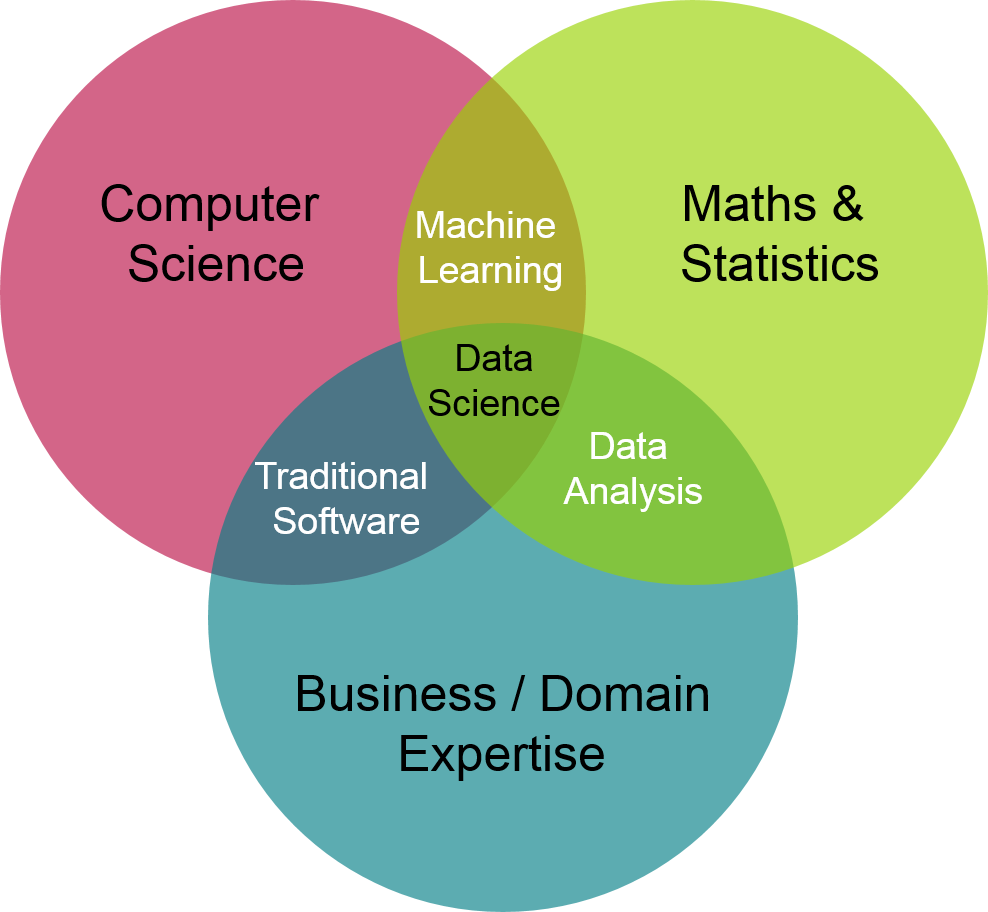
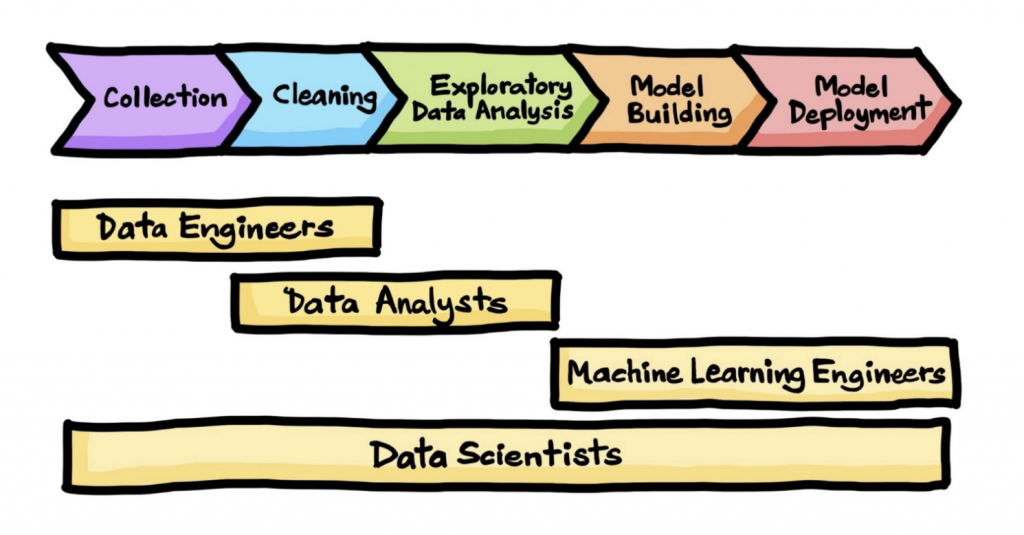
De Data Scientist is oorspronkelijk iemand die modellen kan maken door zijn zakelijke, wiskundige en statistische kennis te activeren met behulp van computerondersteuning. In de nieuwe voorstellingen van het beroep lijkt het er echter op dat de Data Scientist ook de rol van Data Engineer, Data Analist en DevOps op zich neemt.
Vanuit deze observatie wilde Daoud zich verdiepen in de evolutie van het beroep van Data Scientist en deze verandering van opvatting begrijpen: “Hoe zijn we van een specialistische visie, met een Data Scientist die zich richt op onderzoek en prototyping, naar een visie van een generalistisch beroep gegaan dat alles omvat?”
Van oorsprong heeft de Data Scientist als kernactiviteit machine learning, modellerening en prototypen. Deze expertise kan ook uitgebreid zijn in data-analyse en engineering.
We kunnen echter gemakkelijk een lijn trekken tussen wat eerder de verantwoordelijkheid is van een Data Scientist, een Data Engineer en een Data Analist. Bij een bepaalde expertise is er geen twijfel over welk beroep welke verantwoordelijkheid heeft, zelfs als de grenzen in elkaar overlopen. De taken op een project kunnen bijgevolg gemakkelijk worden verdeeld tussen deze verschillende specialisten.
Langs de andere kant is de grens met devOps minder duidelijk: Deployment, productie, het opzetten van een CI/CD-pijplijn… Het is ingewikkelder om te zeggen waar de Data Scientist en Machine Learning Engineer (MLE) verantwoordelijk voor zijn. Voor sommigen is een MLE, een data scientist die aan productie doet. Voor anderen is het een devOps’er die in de machine learning-omgeving werkt. Tot slot zijn er zij die vinden dat we niet meer moeten spreken over de functie Data Scientist, maar wel over Machine Learning Engineer.
In sommige gevallen zijn er duidelijke grenzen tussen de twee beroepen, eerder poreus, maar wel afgebakend. In andere gevallen zijn ze niet zo gemakkelijk te definiëren omdat we niet weten hoe ver de Data Scientist moet gaan en waar de MLE het precies overneemt. Dit komt omdat de beroepen Data Analist en Data Engineer goed ingeburgerd zijn en de MLE een meer recente functie is. Hoewel we niet echt weten waar de grenzen van Data Science liggen, weten we wel dat er een devOps-gedeelte is dat onder de verantwoordelijkheid van de MLE valt. Juist op dit DevOps-gedeelte ligt vandaag de dag meer druk. Daarnaast is het de productiefase waar projecten de meeste valkuilen tegenkomen en hedendaags het meest kritisch lijkt.
Persoonlijke visie
Op persoonlijk niveau kon Daoud als consultant ook zien dat het uitgangspunt van de klant was verschoven. Het was niet langer: “Kan ik dit voorspellen op basis van deze gegevens?” Maar: “Wetende dat ik denk dit kunnen voorspellen op basis van deze data, hoe zet ik het dan in en hoe past het in mijn IS?”. Aan de ene kant bewijst dit dat klanten steeds volwassener worden en zich steeds meer bewust worden van het potentieel van hun gegevens, maar het komt ook overeen met een inflatie van de reikwijdte van de Data Scientist. Tenslotte draagt het ook bij aan de spanning tussen Infrastructuur en devOps.
Deze visie is ook gecorreleerd met een ander feit, beschreven in dit artikel waarin wordt gesproken over de technische tekortkomingen die verborgen zitten in machine-leersystemen. Tijdens de implementatie in de productie moet er inderdaad rekening worden gehouden met zaken die specifiek zijn voor machine learning en Artificiële Intelligentie. Dit suggereert dat degene die het model maakt, rekening moet houden met de kenmerken van de productieomgeving om deze technische valkuil te vermijden. Er is echter een gebrek aan volwassenheid onder Data Scientists omtrent deze kwestie, wat een geheel ander probleem op zich is.
Wat zijn de vooruitzichten voor het beroep Data Scientist?
Hoe kan de komst van deze nieuwe zaken en de rol van Machine Learning Engineer een impact hebben op de rol van Data Scientist?
Een mogelijke mening is dat Data Scientists nieuwe MLOps-vaardigheden zullen moeten integreren. Maar dit is niet het definitieve antwoord op de vraag.
Hoe kan het MLE-beroep worden gedefinieerd?
We kunnen met zekerheid zeggen dat MLE een groeiend beroep is, waar veel druk op staat en waar veel behoefte aan is in de markt.
Maar is het beroep van MLE een tak die voortkomt uit het beroep van Data Scientist , of is MLE de nieuwe naam van het beroep van Data Scientist?
Om deze vraag volledig te beantwoorden, moeten we begrijpen wie de MLE’s zijn in termen van profielen. We kunnen ons baseren op een studie uitgevoerd door LinkedIn, gepubliceerd in 2022, over de sterkst groeiende beroepen in de VS tussen 2017 en 2021. Het beroep van Machine Learning Engineer staat op de vierde plaats in deze lijst. We zien ook de oorspronkelijke banen van mensen die op deze advertenties solliciteren: waaronder meestal ontwikkelaars, Data Scientists en AI-specialisten.
Het feit dat er Data Scientists zijn die deel uitmaken van de huidige MLE’s, geeft nog steeds de indruk dat we te maken hebben met een splitsing in het beroep van Data Scientists tussen verschillende expertises. We zijn daarom geneigd te denken dat het beroep van Data Scientist in tweeën splitst, waarbij elk deel bepaalde verantwoordelijkheden op zich neemt.
Om deze verantwoordelijkheden te definiëren, kunnen we dit diagram raadplegen:
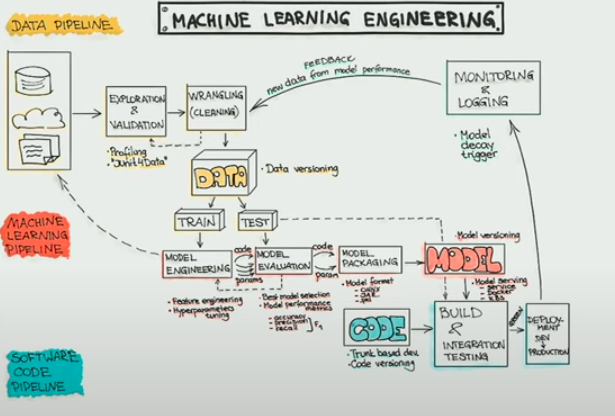
Als we het alleen over expertise hebben, zien we dat er ook een component is die gegevens levert en ervoor zorgt dat deze beschikbaar zijn. Dit alles binnen het kader van bruikbare en toegankelijke datalevering. Dit zou overeen kunnen komen met de rol van Data Engineer. We zien ook dat er expertise nodig is aan de productiekant van modellen. En dat de verwachte deliverable van het machine learning-gedeelte een model is. Dit zou overeen kunnen komen met de rol van de Data Scientist. Ten slotte kunnen we een derde expertise onderscheiden die, vanuit dit model, code produceert met een test & build gedeelte. Uitgaande van de code die bijdraagt aan het produceren van een model, zullen we applicatiecodes gebruiken om het model te integreren en in productie te nemen.
De druk op de Data Scientist komt voort uit het feit dat ze steeds vaker gevraagd worden om een derde expertise te beheren, terwijl het gemakkelijk in de functie van de MLE zou kunnen passen. Zo geeft bovenstaand diagram goed weer waar de verschillende beroepen zich zullen stabiliseren. Daarnaast wordt er geconcretiseerd wat er van welke rol wordt verwacht en waar de overgang ligt tussen de Data Scientist en de MLE. Beide beroepen zullen zich dan opnieuw specialiseren omdat het voor niemand mogelijk is om de hele keten te beheersen.
Om deze overtuiging verder te bevestigen, voerde Daoud een analyse uit bij 80 vacatures, waaronder 40 Data Scientist vacatures en 40 MLE vacatures. Voor elke functie werden 20 aanbiedingen op Welcome to the Jungle en 20 aanbiedingen op LinkedIn geobserveerd. Voor elke functie werd geanalyseerd welk percentage van deze aanbiedingen competenties vermeldde in data-engineering, data-analyse, business understanding en devOps.
Welke expertise worden gevraagd voor de beroepen Data Scientist en MLE?
De volgende resultaten werden verkregen:
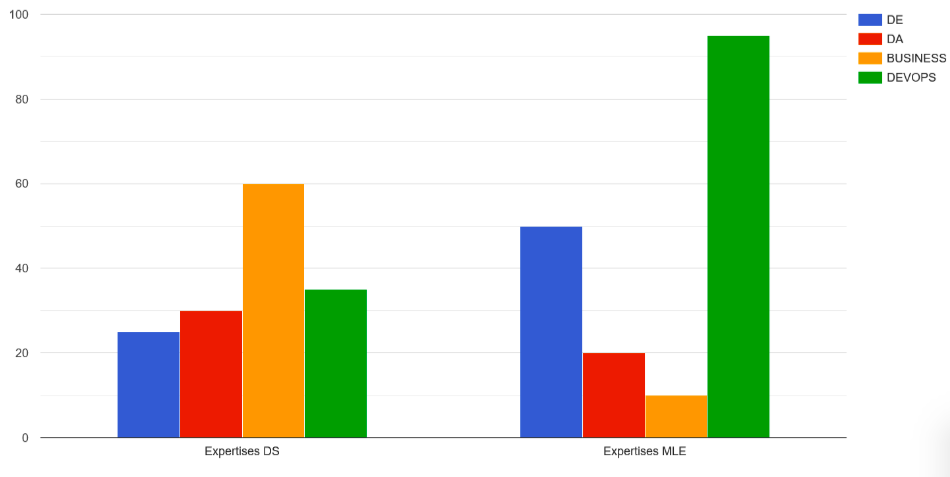
Voor Data Scientist vacatures is de verdeling van gezochte vaardigheden als volgt:
- Data engineering voor 25% van de advertenties,
- Data-analyse voor 30% van de advertenties,
- Zakelijk inzicht voor 60% van de advertenties – In de meeste gevallen gaan we ervan uit dat het voor een Data Scientist essentieel is dat hij de sector waarin hij werkt kent of er interesse in heeft.
- DevOps voor 35% van de advertenties,
- En machine learning vaardigheden in alle advertenties.
We zien dat een Data Scientist iemand is die de data kent en van wie gevraagd wordt interesse te hebben in de business en deze goed te begrijpen.
Voor MLE-vacatures is de verdeling van de gezochte vaardigheden als volgt:
- Data engineering voor 50% van de advertenties,
- Gegevensanalyse voor 20% van de advertenties,
- Zakelijk inzicht voor 10% van de advertenties,
- DevOps voor 95% van de advertenties.
Deze resultaten suggereren dat de MLE wordt aangeworven in een bedrijven waar men al weet hoe men voorspellingen moet maken. Maar moet je als MLE ook over echte machine learning vaardigheden beschikken? Het korte antwoord is JA. Men moet op zijn minst het model kunnen evalueren, zij het niet zeer grondig. Een bedrijf moet op zijn minst te weten komen hoe ze het model kunnen en moeten monitoren. Daarom ligt de verantwoordelijkheid van de Data Scientist bij de juiste KPI te definiëren. Waarna monitoring kan worden uitgevoerd door de MLE.
Tot slot, althans volgens recruiters die Data Scientists en MLE’s werven, zoekt men verschillende expertises voor beide beroepen:
Data Scientists moeten zakelijke expertise beheersen om voorspellingen te kunnen doen. Ze zullen daarom niet worden vervangen door MLE’s, van wie deze competentie niet wordt verwacht. Dit zijn dus twee complementaire rollen waarbij elk zijn specifieke vaardigheden bezit, die de andere niet heeft.
Verschil tussen een MLE en een Devops
De MLE is verschillend van een DevOps omdat hij niet alleen code viseert, maar ook een model en data nastreeft. Hij brengt iets in productie dat vandaag werkt, maar niet noodzakelijk op lange termijn. Dit verschil rechtvaardigt de splitsing tussen deze twee beroepen in de wereld van Data.
We publiceren regelmatig artikelen over web- en mobiele productontwikkeling, data en analytics, beveiliging, cloud, hyperautomatisering en de digitale werkplek.
Follow us on Medium om op de hoogte te blijven van de volgende artikelen en je vakkennis in de gaten te houden.
Je kunt onze publicaties en nieuws ook vinden via onze newsletter, evenals onze verschillende sociale netwerken: LinkedIn, Twitter, YouTube, Twitch en Instagram.
Meer weten? Check onze website en job offers.
Geschreven door
Author








