
A common challenge that many Data Science Teams are facing, is moving beyond the experimental stage of their use cases towards an industrialization stage that is fit for deployment. The discipline – which takes care of enabling stable workflows for Machine Learning (ML) to create production-ready models – is a term coined Machine Learning Operations or MLOps.
Want to know more about MLOps? Check our recent article: From ML Models to Business Value: A three step approach to clear the most common hurdles
The following article presents an implementation concept of MLOps that leverages Microsoft Azure and Databricks. While the article is oriented toward this tech stack, many introduced elements can be applied generally. An instance of this approach was also successfully implemented at our client Deutsche Automobil Treuhand (DAT). A fundamental element of successful MLOps is an alignment of the different groups that are involved in the ML process, such as Data Scientists for exploration and modeling and ML Engineers who are more concerned with deploying the developed models in a consistent and reproducible manner. The detailed process below ensures a smooth transition between the Data Science and the ML Engineering team. To achieve this, we apply a hybrid approach of leveraging Databricks Notebooks which are great for exploration, feature engineering, and prototyping. We then augment the notebooks with development inside of an IDE (Integrated Development Environment), to create modularized and production-ready code which is also used by the notebooks themselves.
Challenges within MLOps
Data Quality
In contrast to traditional software development – where the code ultimately determines the quality of the final product – in ML the data and the model have a significant impact on the output. Therefore, data quality (DQ) is such an essential component of well-functioning MLOps.
Data Versioning
Besides the data quality, it is essential to keep track of the data, which was used to create and train a particular model and to detect changes in DQ. This is where the concept of Data Versioning comes in, acting as an analog to code-versioning with Git, but for data. While there are nowadays many ways to accomplish this, one great possibility is to use a Delta Lake on Databricks, which provides Delta Tables. Delta Tables offer versioning of datasets in an efficient manner.
Model Tracking
Besides Data-Versioning there are many other aspects, which must be taken into account for well-functioning MLOps. Figure 1 illustrates some of these challenges by visualizing on one hand the challenges of a single Data Scientist regarding all the elements that need be tracked, such as the model-artifacts or the environment to ensure reproducibility. This also involves different deployment options for different models which might be requested. On the other hand, efficient collaboration must be ensured among the Data Scientists to avoid the duplication of code and/or incidences of reinventing the wheel.
The tracking and registration of all model elements is where the Open-Source package MLflow comes in, which is also closely integrated, as a managed-version, into Databricks. To avoid duplication of code and ensure efficient collaboration, the IDE side of our hybrid approach is leveraged. Within the IDE the ML-code package was developed, which is then tested and built with CI. This python package can afterward potentially be used in every phase of the ML project. Examples from our project at DAT are utilities for data-loading and deployment, as well as ML code (models, trainers, data loaders, etc.) and custom MLflow-code for wrapping a newly created model for deployment purposes.

Figure 1: Collaboration challenges within MLOps
The MLOps architecture for Azure and Databricks
The above-mentioned usage of MLflow, as well as the development of the ML-code package are a core part of our MLOps architecture for the stack consisting of Azure-components and Databricks that is displayed in Figure 2. Since both aspects affect each part of the displayed ML-workflows they are both displayed as bars at the bottom and top, respectively.
On the left-hand side the classic Data Science steps are visualized, consisting of an initial step of data-ingestion and preprocessing, as well as the feature engineering. Once the dataset for a ML training is ready, it can be saved in a Delta Table. Within a Data-Pipeline this data belongs to the Silver-Layer, which essentially corresponds to cleansed and conformed data that enables ML to create a new version of the data.
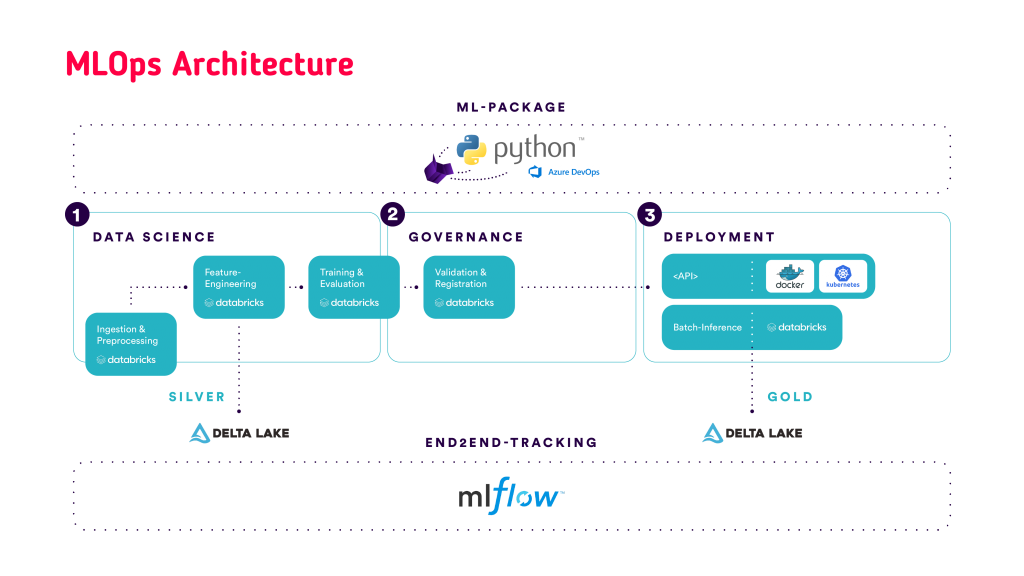
Figure 2: Overview of the MLOps architecture for Azure and Databricks
After these “classic” Data Science steps there is at first a Validation-Gate with criteria that can be defined in conjunction with the Product Owner and other stakeholders. This step is essential to enforce the model governance and to meet potential additional demands such as fairness or explainability. Furthermore, as part of the governance, a model can be moved into a “staging”- or “production” phase to signal a specific maturity-level. The saving of the model in a separate registry (= registration), and as such a secure availability in an isolated environment, is enabled by MLflow.
After a model is registered and staged to “Production” it can be leveraged for different deployment styles, with Batch-Prediction/Inference and model-serving via API being the most prominent ones. Especially the Batch-Prediction case can be greatly covered by Databricks Notebooks and the Delta Lake. The notebook can load the MLflow-model from the remote location (also for several Databricks workspaces possible), execute the predictions afterward and save them in the Delta Lake. Since this data is curated for business applications, i.e. the consumption by dashboards, it corresponds to the Gold Layer within a Data-Pipeline. On the API side, there can be, depending on the needs, a fully customized solution with a custom API and self-hosting, or an elegant ready-made data product, where an API endpoint is automatically created for the MLflow-model from within Databricks.
Smooth transition between Data Science and Ops-oriented tasks
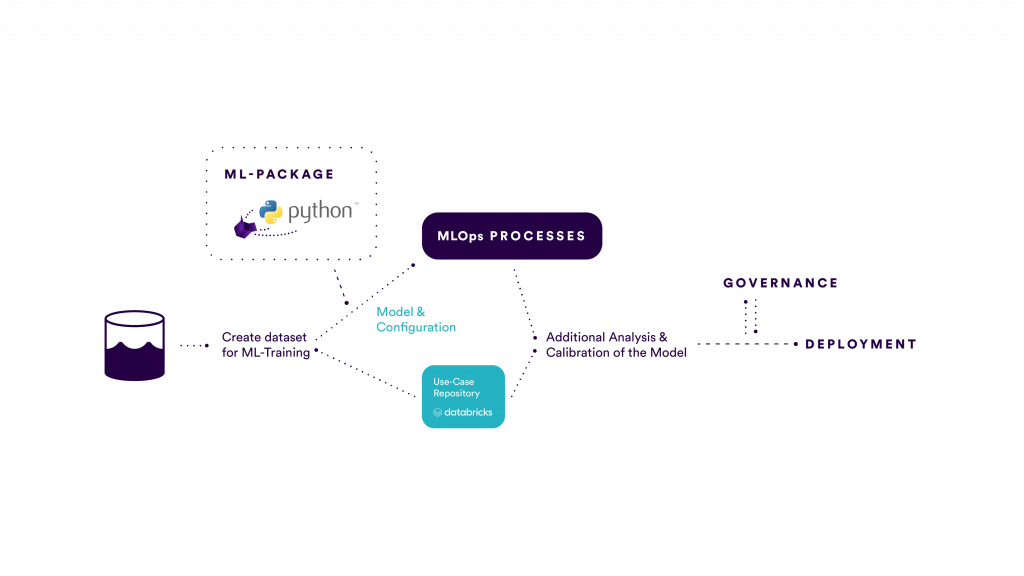
Figure 3: Interaction between Data Science & MLOps
While Figure 2 describes the general ML workflows, it is not yet entirely clear how an efficient collaboration between the Data Scientists and the ML Engineers can take place. Figure 3 aims at shedding light on this aspect by visualizing the workflow of a Data Scientist, when implementing a new use case. The steps initially involve the usual data science steps from Figure 2 and then accessing the separately developed ML-package for choosing a particular model and training it with a train-script and a chosen configuration.
Depending on the Data Scientist, a contributor role to the ML-Package is also possible. Furthermore, all tracking aspects are also abstracted away from the Data Scientist, which enables a focus on additional analysis and calibration after the training end-evaluation of standard metrics. The use case specific code would then be managed in a separate repository, which is developed from within Databricks. After these steps are conducted the model is entering the governance step and is then passed on to the ML Engineers for deployment.
What are the main benefits?
The presented approach for stable MLOps on Azure and Databricks offers many benefits, which can be summarized as follows:
- Smooth transition and communication between Data Scientists and ML Engineers
- Quick implementation with many individualization and customization options
- Significant speed up from PoC to Production Phase
- Ensure high scalability of developed ML code through simplified reuse
Not sure where to start?
It is key to emphasize that the approach is modular by design and each component can be realized with different levels of sophistication, whereby the base level implementation already brings a significant speed-up and improved control within ML workflows. At Positive Thinking Company, we offer a comprehensive range of services to achieve an effective and reliable MLOps initiative across many organizations. Contact our team to learn more or have a look at our Data & Analytics capabilities.

Thanks to our
Author









