
- Foreword
- 12-question organization self-assesment
- 1. Data-Driven or Data-Inspired?
- 2. Do you have a clear problem to solve?
- 3. Do you have the necessary analytical and statistical skills?
- 4. Do you have the right definition of data science?
- 5. Does your organization have the required technological maturity?
- 6. Do you know enough about your data?
- 7. You have hired a Data Scientist. Now what?
- 8. Can you make the difference between data science and software development?
- 9. Do your data teams communicate enough with the business?
- 10. Have you nominated a champion?
- 11. Did you underestimate the importance of data democratization?
- 12. Have you chosen your partners well?
- Conclusion
FOREWORD
It all starts with a Google search
Let’s start with a quick analysis of the number of weekly searches worldwide for the terms “data science”, “Big Data”, “data-driven”, “machine learning”, and “artificial intelligence” over the past ten years. We can see a real interest in searches about artificial intelligence, compared to the other terms. This demonstrates that we may not be aware enough of the concept of being data-driven and we simply prefer other keywords that we have undoubtedly heard more often.
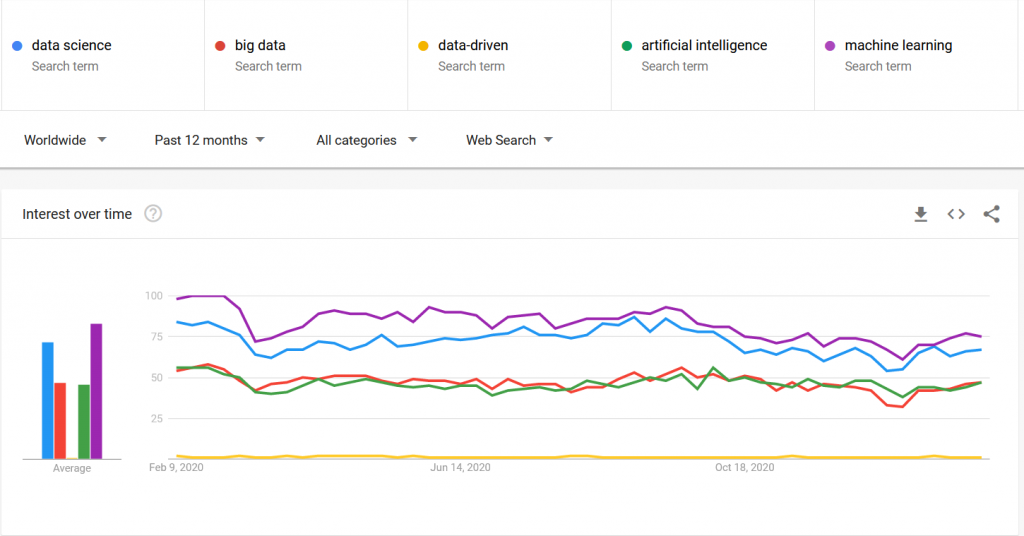
Most organizations want to create value from their data. They want to try their hand at data science, Big Data, and artificial intelligence (AI). These topics have become so popular that there are now plenty of books, articles, and blog posts about them. Victims of their own success, these keywords may conceal a more important concept: being data-driven.
But what does it mean to be data-driven? To have a “data culture”? And most importantly, how do you know if your organization is ready to survive in this new data-driven environment?
A caricature not far from reality

Let’s get started! Your organization has hired a data scientist. Graduated, more than qualified according to his/her resume. Starry-eyed, you are eager to start working on innovative projects with this new member of your team. You talk with your customers and investors about this new endeavor of yours, a project using AI. You make predictions and talk excitedly about your project. But after a few months, the project is far from meeting your expectations. You thought that you had an algorithm capable of making certain predictions correctly and even carrying out some decisions completely on its own. You were convinced that you would have this amazing tool in no time, with extraordinary graphics, powered by this trendy neural network algorithm. An algorithm seemingly capable of mimicking the human brain and solving every problem under the sun. You talked about it over drinks, during coffee breaks, and at team-building activities. But you have nothing.
In fact, even the dynamic reports running real-time forecasts do not seem to work. To make it worse, your overqualified data scientist does not seem like the right fit for the project. You would at least expected them to have proven and confirmed the extraordinary potential of your product, but they presented lackluster results in recent meetings. The analyses fall short of your expectations. You are disappointed and downright frustrated. You start to think that all these stories about AI are nothing more than fantasy. On top of everything, you have recently heard people talking about a new trend, a revolutionary tool that cuts down the time it normally takes to complete a task by a factor of 100. It is seemingly possible to automate lots of analyses. In fact, you just realized at conferences that your recently hired data scientist’s activities can be automated.
You start to think that all these stories about AI are nothing more than fantasy.
As for your IT team, they are constantly complaining that they spend a lot of precious time having to help your data scientist, who is always asking for more data and better quality data, without mastering software development concepts, like: design pattern? CI/CD? Deployment? Scaling? QA?
Meanwhile, your data scientist had dreamed of working on a technical project where they could apply their knowledge of the latest state-of-the-art algorithms, but instead, 80% of their time is spent cleaning and preparing data. They spend 80% of their time pleading with teams to keep data accessible, documented, and not disseminated among other departments and/or employees (Rogati 2017). The remaining 20% of the time is spent in meetings, dealing with the company’s security policies, carrying out discussions on Slack/Teams for more data of better quality, questioning the source of the data that is already available, tinkering with a work environment where they have no rights and cannot install anything, trying to convince managers of the importance of having a data-driven system, and working with highly advanced models that no one else appreciates. They have devoted the past few years to understanding the most advanced concepts in statistics, algebra, and machine learning, which are of little use in their day-to-day job.
What are the reasons for this situation? Who is responsible? In this article, we encourage you to ask yourself the right questions and to take a closer look at your organization’s data culture to identify its limitations. Then, in future articles, we will provide you with the information and solutions you will need to make your data transformation a success.
12-question organization self-assesment
1. Data-Driven or Data-Inspired?

A data-driven company is an organization that has forged a data culture. According to this approach, data is the core of the business, it is organized and examined with only one goal: improving the organization’s business strategies.
There are many ways to evaluate a company’s data maturity. Some focus on the amount of data being generated, while others talk of the sophistication of their IT architecture or the talented people they have managed to hire. However, there is one simple way to identify whether or not a company is data-driven: through its decision-making processes. Lots of organizations think that they are data-driven because their decision-makers glance over some numbers, form an opinion, and then make their decision. Unfortunately, these kinds of decisions are “data-inspired” at best, meaning that they are made based on a few numbers and use immediate knowledge, automation, and intuition to reach a conclusion (Kozyrkov 2019; 2018). Numbers and graphs are involved in the process, but ultimately, they have no real influence on making a decision.
There is one simple way to identify whether or not a company is data-driven: through its decision-making processes.
We unconsciously use judgment heuristics1 that often leave us asking ourselves the (biased) question of To what extent does the observed data support my beliefs? If the data supports our beliefs, we have more confidence in it. As much as possible, we systematically seek out pretexts that allow us to maintain our initial opinion (Kahneman et Clarinard 2012). As a result, an organization’s decision-making system comes not only from observation of the facts, but also from elsewhere. Sure, data was present, but throughout the decision-making process, only these heuristics really dictated the strategy to be pursued. Because intuition may have proven useful in the past, some decision-makers prioritize their own beliefs and decision-making methods and may sometimes even show reluctance toward analytical approaches derived from data integration (Yao 2017). However, as Daniel Kahneman has theorized, these intuitions are justified when they are formed in a context where situations recur with similar characteristics and where individuals receive clear and immediate feedback. In other situations, they may lead to bias and errors in decision-making. For example, one major form of bias in “inspired” decision-making is confirmation bias, which affects how we observe facts considering our own beliefs. Another example of bias is the IKEA effect2 that motivates us to place disproportionate value on products and concepts that we have developed ourselves.
Ultimately, in a volatile and ever-changing world, one thing is clear: even though intuition may have worked in the past, such approaches are random and subject to our many natural cognitive biases.
2. Do you have a clear problem to solve?

Before starting to invest in the latest data technologies, your organization needs to have a clear and well-defined idea of the problem it is trying to solve.
- Why is it necessary to solve this problem?
- What metrics can be used to measure the success of this solution?
The key to a successful data project is to perfectly define the problem and establish guidelines for your decision-making system before even starting to work on your data.
As W. Kimball theorized, we need to be very careful not to fall into the easy trap of making type 3 errors (Kimball 1957). You can have to the best data science team in the country and still make them answer correctly to the wrong question. The corollary of this is that it would be better to provide a rough answer to the right question, rather than the perfect answer to the wrong question. Data science alone cannot find the answer to a poorly formulated question. No algorithm is so advanced that it can achieve this feat.
At best, a poorly defined problem will slow down your project and your teams. Therefore, it is so important to focus on what you are trying to achieve, not on the procedure you will use to do it. Do not confuse the end with the means.
3. Do you have the necessary analytical and statistical skills?

If you torture the data long enough, it will confess.
Ronald H. Coase
In a group of 366 people, at least two of them share the same birthday. This coincidence can be found in a smaller group of 25 people, where the probability of two people having the same birthday is greater than 50%. Gilles and Marie both celebrate their birthday on October 13. Data dredging consists of looking for other similarities between them, such as:
- Do they both have dogs?
- Do they both have an engineering degree?
- Do their fathers have the same name?
- Did their mothers practice yoga during pregnancy?
- And so on.
If we look carefully at the thousands of possible similarities between Marie and John, each with a very low probability of being true, we will always find one similarity. The biased conclusion may be that people born on October 13 are more likely to be engineers or even that women who practice yoga during pregnancy are more likely to have children born in October who will become engineers.
What just happened? We have fallen into the trap of data dredging. This term describes the misuse of data analytics to find models that appear to be statistically significant. Don’t you think this example sounds a bit silly? Yet this very phenomenon is responsible for leading the scientific literature into a reproducibility crisis, whereby reproducing the experiments described in scientific articles do not yield the same results.
The same principle applies for your organization, where data is tested so much that you are likely to end up with meaningful tests whose subsequent conclusions cannot be reproduced.
To avoid this, it is essential to understand the importance of (and method for) separating the data that allows us to make assumptions from the data used to test those assumptions (Kozyrkov 2020b). This involves a clear understanding of the difference between analytical study and statistical study (Kozyrkov 2020a). Analytics allows us to form hypotheses to improve the quality of our questions. Statistics, meanwhile, allows us to test these hypotheses to improve the quality of our answers. It allows us (among other things) to test whether the phenomenon identified in the analytical study data can be generalized and applied on a larger scale. Finally, more in-depth skills can help you avoid common cognitive biases3 in a study.
4. Do you have the right definition of data science?

Let’s be honest. There is no consensus on the true definition of data science. After all, is it just a passing fad? Because of this lack of clarity, we have found that, during their technical interviews, some organizations lump a wide range of topics into the field of data science, such as SQL, web programming, Scala, design patterns, regression, gradient boosting, data structures, algorithms, statistics, test-driven development, management, and machine learning. Data science has become a rather abstract concept representing many different roles and principles.
On the other hand, having a web application connected to a database does not necessarily make your organization data science-savvy. Data science is about more than simply using data. If that were the case, virtually all organizations would use Data Science. On the contrary, data science makes data useful and supports decision-making. As a direct result of its use, organizations can develop strategies that will benefit the business in many different areas.
5. Does your organization have the required technological maturity?

Everyone is talking about AI. Not a day goes by without hearing about how it will change our projects, our work, and even our own lives. However, these announcements omit a key point for any organization seeking to fully exploit AI: it is important to know and understand the algorithms being used, but more importantly, it is vital to ensure the existence of a well-oiled technological mechanism.
Ultimately, the purpose of any data project is to be connected to your existing system. This requires a full integration of the model within your organization’s information system. But it is very difficult to integrate an AI model into an enterprise-level IT architecture. Organizations often spend more time thinking about the models to use for their project rather than on defining how this new model will fit into their IT architecture and ultimately their business (Tse et al. 2020). In a data project, the fraction of code devoted to the AI model itself is not necessarily the biggest. AI itself is a much larger system, and to make the most of its value, you need to start with a well-designed production environment. This means that a failure to plan the architecture of this technological environment from the beginning will hinder your future AI projects, in terms of both a technical and project management perspective. You could even say that AI is ineffective or just a passing fad, when in reality, it shines a light on a technological system’s lack of maturity or the lack of management perspective. Like a mirror, AI amplifies and highlights an organization’s strengths, and weaknesses.
Therefore, what you may consider to be a failure in an AI project may actually be rooted in technical and managerial problems and limitations within your organization. There is more than a single AI project at stake, spotlighting a real need.
6. Do you know enough about your data?

All AI projects require data. But do you know how to answer these questions correctly?
- Do you have data?
- If yes, how much of it do you have?
- Do you know exactly where your data comes from?
- Do you have the rights on it?
- Do you have a policy for tracking your data?
- How quickly does your data grow?
- Does your organization have the infrastructure to reliably store, manipulate, and deliver your data?
- How do you make it accessible?
For example, your data project may be compromised if your employees are still working independently on desktop computers with no shared databases that can be searched by all members of your organization. In addition, because AI sometimes needs large volumes (the type of files that cannot be opened with Excel) or even very large volumes of data (Big Data), your project may question the efficiency of your code. A poorly written script can drastically drag down parts of your analysis pipelines. But in a company where deliverables must be produced constantly, it can be confusing to see your data team “wasting time” on optimization tasks that do not seem to add any value to your project.
Are you able to point your finger at any piece of data in your information system and quickly access its documentation, know its origin, and the steps leading up to its current state? We are often tempted to confuse data quantity and data quality. Your data project needs data that is clean and clear.
Remember that an astronomical amount of disorganized, undocumented data without data lineage4 will, at worst, be unusable and, at best, be usable only after a very time-consuming cleanup step that you likely will not have considered during your project planning phase.
7. You have hired a Data Scientist. Now what?

Some organizations, looking to launch into data analytics, hire a Data Scientist. After all, we have all heard that being a data scientist is the sexiest job of the 21st century. But that is not exactly right. Organizations have been convinced that they need a Data Scientist when, in reality, they need a Data Analyst.
Sure, a Data Scientist partially fill the role of a Data Analyst, but then you risk building frustration on all sides. To keep it simple, in order to know whether you need a Data Analyst or a Data Scientist, ask yourself if you are trying to predict new events (Data Scientist) or understand historical events (Data Analyst)(Faulkman 2020).
Hiring a Data Scientist to carry out a traditional analysis is like trying to fish with a rocket launcher. If you are uncertain, it should be best to hire an Analyst first.
8. Can you make the difference between data science and software development?

Data science uses many methods found in software development. Because of these similarities, organizations endeavoring into data often build their data team from their IT department.
Many project managers are attracted to the belief that data science teams can be managed with the same processes as development teams. Although these two disciplines often share some similarities, there are major differences between them. For example, data science focuses more on exploring and discovering insights, where software engineering typically focuses on implementing deliverables in response to a specific request. The requirements for data science projects might be vague because of the field’s inherent exploratory aspect, while ambiguity in a software development project is more likely the result of an initially poor definition of what the customer needs.
Therefore, it can be a real challenge to try to manage a data science project as you would manage your development projects.
9. Do your data teams communicate enough with the business?

An organization can design a very good data team with highly skilled engineers. However, these data teams are traditionally created within the IT or Business Intelligence department, where they are isolated from decision-makers and other units. A silo system with compartmentalized teams will result in inefficient corporate governance.
To make the most of data’s potential in your strategy, you need a data culture that is fully infused into each and every department and business line. Effective and sustainable data use requires everyone’s involvement, interest, and constant interaction. All areas of the business are responsible for managing their own data, and defining a data governance strategy is essential.
An easy way to identify whether or not everyone is on the same page with data culture is to see if all your employees have a clear idea of what data is, along with its challenges, the data governance policy, data science, and its many potentials and challenges. Also, pay attention to whether or not your employees make the effort to communicate with the data department about technical issues they may encounter each day, the frustrating steps they may encounter in the course of their analyses, and so on. Similarly, your data team needs to understand business challenges, including business objectives and constraints.
As Master Yoda said, communication is the key, and everything will come from the top management. If your employees find that the data team’s input is important for the organization’s decision-makers, it will become important for them, too. The opposite being also true.
10. Have you nominated a champion?

As mentioned earlier, change will first come from your organization’s top management. Organizational leadership must be supported by a vision, actions, and a budget.
The executive team must have general knowledge of the challenges of data governance and the research and analysis steps. To achieve this, it is important to emphasize that good communication necessarily involves one key concept: humility. If you do not feel comfortable asking the data team any questions, you will not understand their goals and challenges. And if you do not understand these aspects, you will not have the critical view necessary to properly manage a data project or develop a good data-driven strategy.
To help you with this initiative, it may be best to focus on a champion who holds a key place at the decision table (Yao 2017). Someone who can interact with both the data department and executives. And your champion should not simply be the “geek” in your organization. They need to embody this key role and be recognized by everyone.
11. Did you underestimate the importance of data democratization?

Practically every company is flooded with data. Collecting a huge amount of data, however, will not help you understand it, let alone derive value from it. Poor data control delays a company’s digital transformation initiative.
According to a recent Censuswide survey5 of more than 7,300 decision-makers, only 24% are confident in their ability to use their data. Also, while 92% admit that it is important for their employees to be educated about data, only 17% say their company is taking significant steps in this direction.
This demonstrates that, even if companies are aware of the importance of good data governance, they struggle to establish a data culture. Such a culture must not exist only within the IT or data department, but must take root throughout the organization. All areas of the business are responsible for managing their own data and must be able to share it easily. For example, if a certain type of data within your organization is held only by a few employees on an Excel file stored on their computers, there is a problem. If a certain type of data is no longer accessible because it is controlled and held only by one individual employee (who is not available when you need the data), there is a problem.
These examples easily highlight the maturity of your data governance. For your organization to become truly data-driven, you need to change your mindset, attitudes, and habits by making data a central part of your company’s identity.
12. Have you chosen your partners well?

AI is unprecedentedly trendy these days. And like any trend, it attracts lots of players: some skilled and developing viable and reliable solutions, others with over-boosted marketing arguments resulting in excesses. The phenomenon is such that companies claiming to be using or developing AI systems are actually using humans (often at a lower cost) to automate certain tasks that the AI they sell is supposed to perform (Schmelzer s. d.; Solon 2018).
This makes it difficult to differentiate what is true from what is false and to discern in-depth expertise from exaggerated approximation. Perhaps you have set up a project with a partner who fails to explain technical principles or answer your questions clearly. The opposite being also true. You should not let yourself be wooed by beautiful storytelling or a technical explanation similar to science fiction. Also, stay away from companies that do not know (or are afraid to) say “No” to any idea you put forward. This might be a “no, it’s not possible to address that issue because…” or “no, you don’t need AI to do that because…”. Many ideas that are relevant at first glance will not withstand careful and expert analysis. It may be because you do not have the right data, enough resources, or simply because there is no viable solution to deliver within the allocated time. There are so many reasons that might lead to a negative response. Sometimes, the most competent person in the room is the one who will tell you “No”.
Sometimes, the most competent person in the room is the one who will tell you “No”.
The fact is that some companies will not ask you the right questions. They will not try to accurately understand your challenges, goals, or motivations and will rush to create the solution you are looking for. If they would only attempt to truly understanding your challenges, they would have been able to offer you a better solution, such as replacing your rocket launcher with a fishing rod if you wanted to fish for salmon, just as an example.
Finally, some companies will lock information down. If you do not learn the technical side of things throughout the project, it is probably because they limit the much knowledge they share with you. The basis of any healthy relationship should be the freedom to ask questions and get answers and other information in order to improve your understanding.
Conclusion
We have entered the data age. Many industries are turning to a new data-driven way of operating, where decision-making relies on a continuous analysis of large amounts of data. This strategy has the potential to significantly improve the efficiency of our organizations and even our relationship to work. However, there are many challenges, both human and technical, that need to be mastered in order to use your data efficiently. And every challenge encountered in the course of your data project reveals something about your organization’s maturity.
As you know, being data-driven is not about owning the latest Big Data technologies or an armada of Data Scientists. Although useful, this is the result of a well-designed data strategy and not its cause. Nor is it a one-off effort. Before reaching a destination, one must first undertake a journey.
Based on our experience, this article asks questions that provide an overview of an organization’s level of preparedness. In our upcoming articles, we will try to provide concrete thoughts and solutions that will help you lay the foundation for a data-driven organization and an effective data culture.
Sources:
1Judging heuristics are automatic, intuitive, and quick mental operations. Heuristics save people time because they do not take into account the complexity of the information relevant to the situation. However, they may lead to bias and errors in decision-making.
2The IKEA effect is a form of cognitive bias in which individuals place disproportionate value on products and ideas that they have created themselves.
3(« Statistical Fallacies and How to Avoid Them » s. d.)
4Data lineage is a process designed to map out an information system. It allows you to view the lifecycle of your data in order to answer questions about where the data comes from and what transformations it has undergone.
5(“Data Literacy: Why is it important for your company?” n.d.)
« Data Literacy : Pourquoi est-elle si importante pour votre entreprise ». s. d. Qlik. Consulted on August 31, 2020. https://www.qlik.com/fr-fr/bi/data-literacy.
Faulkman, Tyler. 2020. « 7 Reasons To Not Hire a Data Scientist · Learning With Data ». April 9, 2020. https://learningwithdata.com/posts/tylerfolkman/7-reasons-not-to-hire-a-data-scientist/.
Kahneman, Daniel, et Raymond Clarinard. 2012. Système 1 / Système 2 : Les deux vitesses de la pensée. Paris: FLAMMARION.
Kimball, A. W. 1957. « Errors of the Third Kind in Statistical Consulting ». Journal of the American Statistical Association 52 (278): 133‑42. https://doi.org/10.2307/2280840.
Kozyrkov, Cassie. 2018. « Data-Driven? Think again | Hacker Noon ». July 2018. https://hackernoon.com/data-inspired-5c78db3999b2.
———. 2019. « The First Thing Great Decision Makers Do ». Harvard Business Review, June 25, 2019. https://hbr.org/2019/06/the-first-thing-great-decision-makers-do.
———. 2020a. « What’s the Difference between Analytics and Statistics? » Medium. April 10, 2020. https://towardsdatascience.com/whats-the-difference-between-analytics-and-statistics-cd35d457e17.
———. 2020b. « The Most Powerful Idea in Data Science ». Medium. August 28, 2020. https://towardsdatascience.com/the-most-powerful-idea-in-data-science-78b9cd451e72.
Rogati, Monica. 2017. « How Not to Hire Your First Data Scientist ». February 2017. https://hackernoon.com/how-not-to-hire-your-first-data-scientist-34f0f56f81ae.
Schmelzer, Ron. s. d. « Artificial Or Human Intelligence? Companies Faking AI ». Forbes. Consulted on August 18, 2020. https://www.forbes.com/sites/cognitiveworld/2020/04/04/artificial-or-human-intelligence-companies-faking-ai/.
Solon, Olivia. 2018. « The Rise of “Pseudo-AI”: How Tech Firms Quietly Use Humans to Do Bots’ Work ». The Guardian, July 6, 2018, sect. Technology. https://www.theguardian.com/technology/2018/jul/06/artificial-intelligence-ai-humans-bots-tech-companies.
« Statistical Fallacies and How to Avoid Them ». s. d. Geckoboard. Consulted on November 24, 2020. https://www.geckoboard.com/best-practice/statistical-fallacies/.
Tse, Terence, Mark Esposito, Takaaki Mizuno, et Danny Goh. 2020. « The Dumb Reason Your AI Project Will Fail ». Harvard Business Review, June 8, 2020. https://hbr.org/2020/06/the-dumb-reason-your-ai-project-will-fail.
Yao, Mariya. 2017. « Applied Artificial Intelligence: A Handbook For Business Leaders ». Mariya Yao (blog). 2017. https://mariyayao.com/books/.

Thanks to our
Author









