
In an age with exponential growth of information (generated either by humans or generative AI), it is a competitive advantage to automatically extract relevant information to answer questions at scale. After focusing on API integrations with LLMs, we now showcase how LLMs are supercharged engines for side-by-side comparison of data sources when integrated into a retrieval augmented generation pipeline.
Therefore, the second tutorial in this series focuses on parallel question answering about multiple documents using Llama Index and Retrieval Augmented Generation, a powerful tool for Question Answering. This article provides a detailed walkthrough of the tutorial, demonstrating how Llama index can be used in combination with LLMs to:
- build an index across multiple documents,
- conduct parallel question answering about those documents and how to cluster the results,
- gain deeper analytical insights by building and visualizing a graph based on the extracted information units.
Introduction to Multi-Document Parallel Question Answering With Llama Index
In this second episode, we delve into the fascinating world of LLMs and their application in building a multi-index subquery engine on top of PDF documents. Our tutorial leverages a Python-based Streamlit application and the widely used Llama Index library to demonstrate this.
We make use of Retrieval Augmented Generation (RAG). In RAG a query triggers a semantic search retrieval pipeline, by computing a semantic vector representation of the query text. This query vector representation is used to find the top k most similar document chunks for answering the question via approximate nearest neighboring filtering using algorithms like “Hierarchical Navigable Small Worlds” (HSNW). Those relevant chunks as context into a prompt template to instruct an LLM to synthesize an answer to the question based on the context of the relevant document chunks.
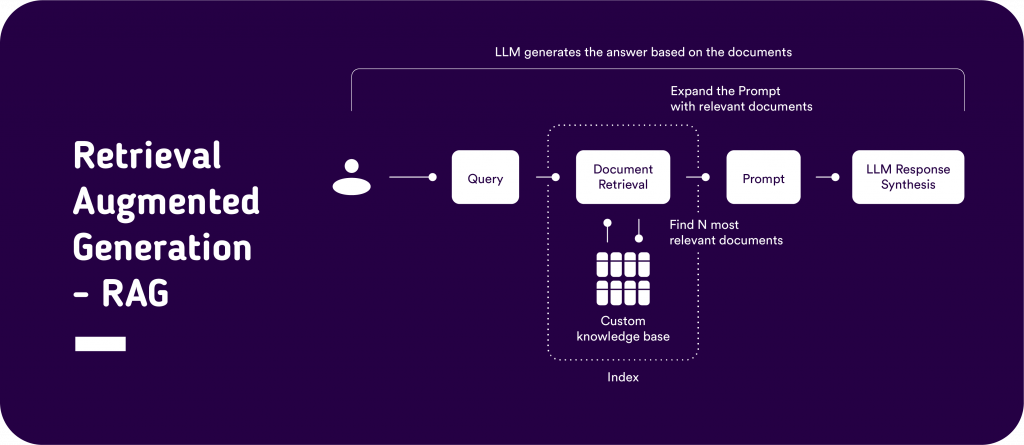
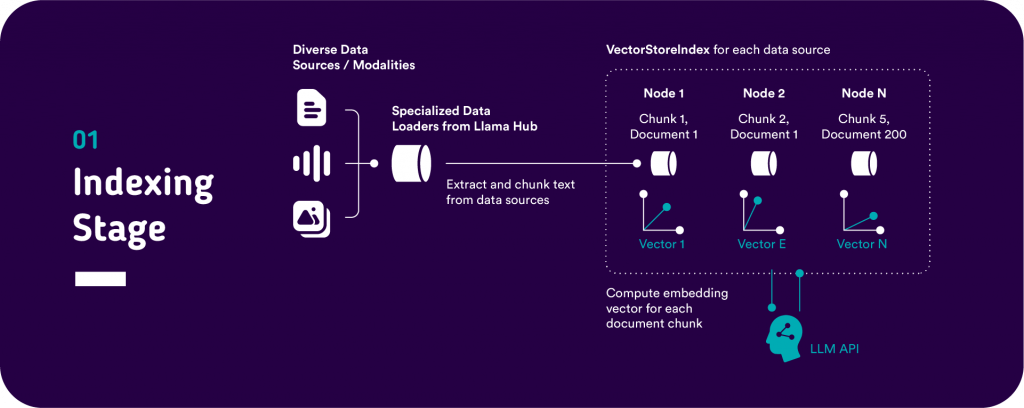
As a result, if we would like to employ RAG we first need to index the documents we would like to serve as a context source for answering the questions. For this purpose, we load the Data with corresponding data loaders (e.g. dedicated data loader for PDF documents) to parse the data to text. Next, a Llama index Node parser is used to split the text into overlapping chunks. Finally, an LLM or SBERT model is used to compute a semantic vector representation for each of the nodes. The text chunk nodes with corresponding document IDs and vector representations serve as an index and the most relevant chunks for a query can be retrieved using ANN filtering algorithms.
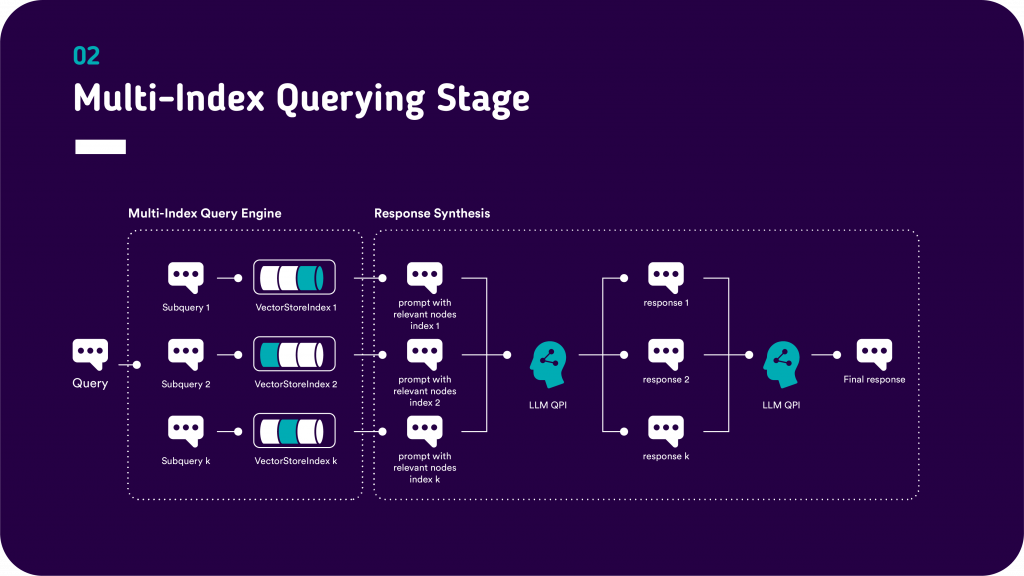
In a multi-index setting, we do not just have a single index but rather multiple individual indices per document source and a subquery engine on top of the individual indices. In this architecture, a query is first parsed to individual queries per index and the answers are generated for each individual index based on RAG (per index). The responses for each individual index are then combined into a final response via a LLM generation step. Thus, the individual responses can still be attributed to the source indices and the answers can be compared side-by-side for the different data sources.
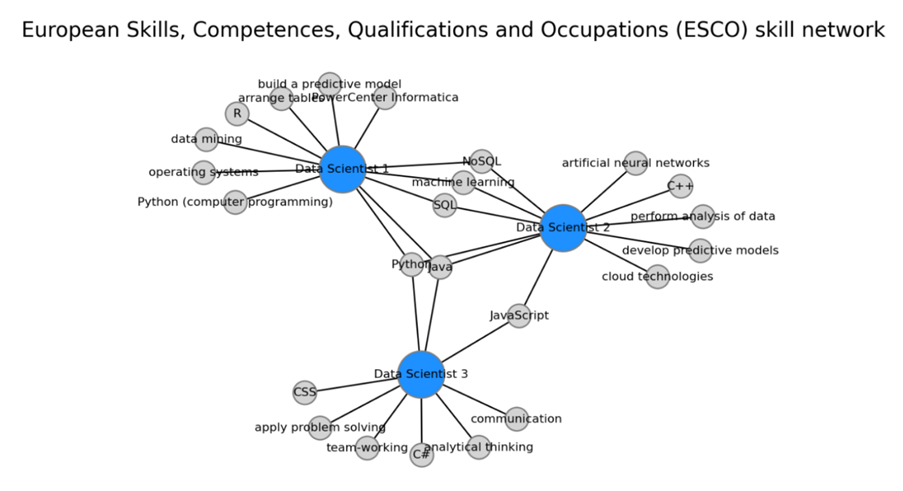
Much deeper analytical insights can be gained by further processing of the extracted responses. For example it is possible to extract soft-skills and hard-skills from Curriculum Vitae (CV) documents of different candidates. Those skills can be normalized by finding the semantically most related skills from the European Skills, Competences, Qualifications and Occupations (ESCO) knowledgebase. By identifying the intersections between skills between job candidates it is possible to visualize the overlap between candidates with regards to their respective skills via graphs. It is possible to quickly see which skills are shared among candidates, which candidates are most similar to each other, and map the candidates to the required skills for the given position.
Technical Implementation of Multi-Index Parallel Document Question Answering
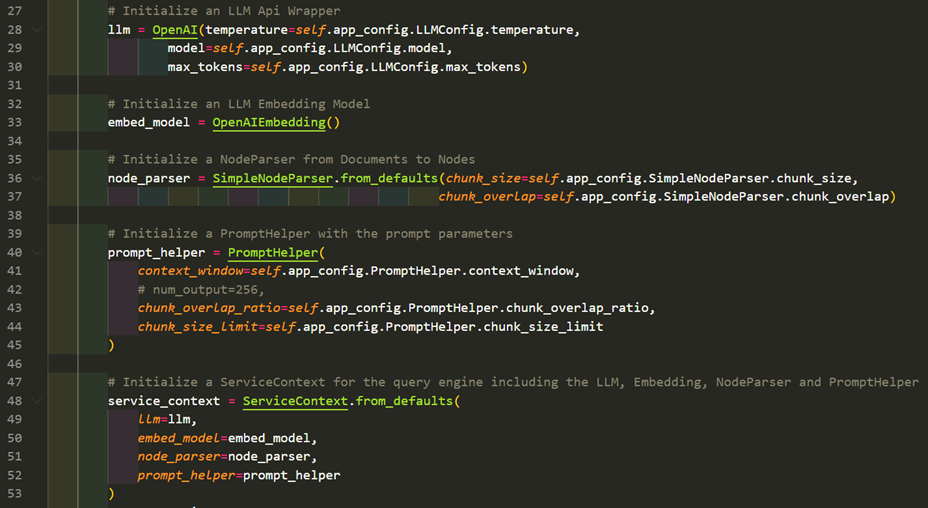
The centerpiece of the parallel document question answering use case is the SubQuestionQueryEngine and the individual indices per document. For this purpose, we configure a customized llama index ServiceContext and thus initialize the following objects:
- llm (Large Language Model OpenAI API wrapper) for response synthesis with custom temperature and a maximum number of tokens
- embed_model (OpenAIEmbedding API wrapper) to compute LLM vector representations of the document chunks to be indexed
- node_parser for splitting documents into text chunks with predefined chunk_size and chunk_overlap
- prompt_helper for filling a response synthesis prompt template with the relevant contexts obtained by the index retrieval step
- service_context integrated configuration of the llama index question answering pipeline
For each document an individual index and a corresponding query engine is initialized. Those indices are stored in a dictionary mapping from the title of the document to the corresponding query engine.

For all of the individual document indices and their corresponding document query engines a QueryEngineTool is initialized. The list of all QueryEngineTools is used to initialize the actual SubQuestionQueryEngine.
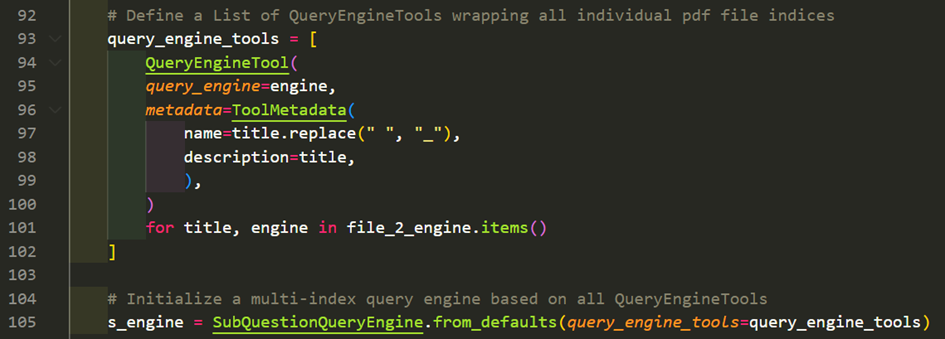
The subquery engine can be used to execute parallel multi-index queries.

Access to the GitHub Repository: https://github.com/PositiveThinkingComp/LLM_Mini_Series_Part_II/tree/main
In the present tutorial, we utilize the Llama Index Streamlit application to:
- Show the simultaneous extraction of answers to individual question from multiple CV documents;
- Demonstrate how RAG can suppress LLM hallucinations;
- Illustrate how SBERT embeddings can be used to semantically cluster responses;
- Highlight how deeper analytical insights can be gained by graph-based analysis.
Exploring Other Potential Use Cases for Multi-Index Subquery Engines
There are many use cases where information needs to be extracted for different objects in parallel. Here is an overview of three typical situations:

Comparison of Different Versions of Long-Form Documents
Multi-index question answering can be used to rapidly spot differences between different versions of long-form documents. By first generating an index for each individual version of a document and then initializing an index on top of those indices it is possible to utilize a Subquery engine to spot differences between those documents, by asking questions about paragraphs to be compared to each other.
Side-by-side question answering can be useful for:
- CV documents
- Product reviews
- Real-estate object descriptions
- Multiple project proposals
- Different versions of documents
Multi-Modal, Multi-Source Data Comparisons
The llama-hub offers a plentitude of different data loaders to parse source data for different source formats into llama index nodes. By utilizing advanced AI-driven image captioning tools like SceneXplain, or speech-to-text converter models like whisper, it is possible to quickly transform image and audio input into the text domain.
Also, multimodal embeddings such as CLIP & BLIB can be used to project text and images into a shared embedding space and can be indexed for a parallel, multimodal, multi-index retrieval step. On top of individual multi-data source, multi-modal indices it is possible to initialize a multi-index subquery engine. This subquery engine can be used to figure out, whether different sources return similar answers and can enrich the context for decision-making and grounding of answers on multiple sources instead of relying critical decisions on a single source of truth.
In conclusion, the utilization of LLMs for parallel question answering does increase the productivity of employees significantly with regards to tasks that required sequential reading of multiple long-form documents. Its time to start thinking about which processes in your company might be parallelized by means of multi-index Subquery engines. Do not miss our next LLM mini-series episode on inserting information from unstructured data into structured templates.
Access to the GitHub Repository: https://github.com/orgs/PositiveThinkingComp/repositories
Subscribe to the Youtube channel: https://www.youtube.com/@Positive_Thinking_Company

Thanks to our
Author









