
Feature Engineering for Machine Learning
PySpark has been the go-to tool for building machine learning pipelines for a while now. The process is straightforward: ingest the raw data, clean it, create features and train the appropriate model.
Most of the time, feature engineering means datasets grow in size, as multiple columns are added to improve the performance of machine learning models in a technique known as ‘One-Hot encoding’. It’s not uncommon for big projects to have hundreds of columns, which make the data bigger and difficult to manage.
Even more important than data size, Spark and specially Parquet files are known to suffer performance issues when there are too many columns. Tag-based features is an approach that attempts to take advantage of PySpark’s native ability to handle arrays since Spark 3.
Leverage the Power of Spark Arrays
The proposed technique means that instead of creating additional columns for each new feature, one single column holding an array of feature “tags” is created. Existence of the tag in the array means the feature is true for that row. Absence means it is false.
As an example, let’s consider we want to create 2 features is_a_or_d and is_october out of the following sample data:
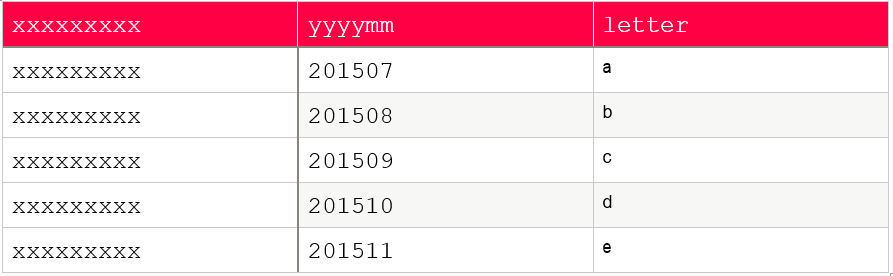
Once applied, our PySpark DataFrame will look like:
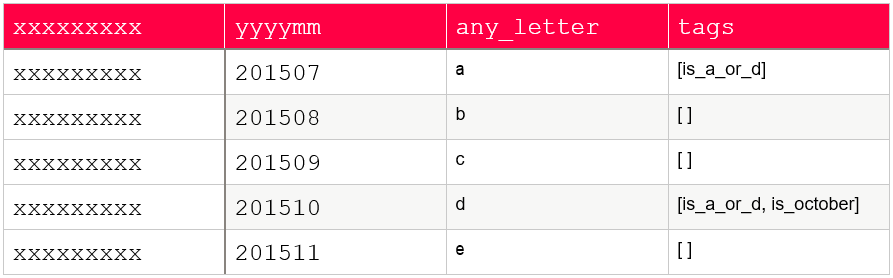
We can observe how this approach makes it possible to create smaller DataFrames while maintaining performance in PySpark / Parquet, which is particularly useful on pipelines where datasets are passed across multiple nodes where an ever-growing number of features are added.
This kind of DataSet can be of course exploded back to the traditional One-Hot encoding shape most Machine Learning algorithms are performant with, just before it is inputted to the model. For the above example, that would look like:
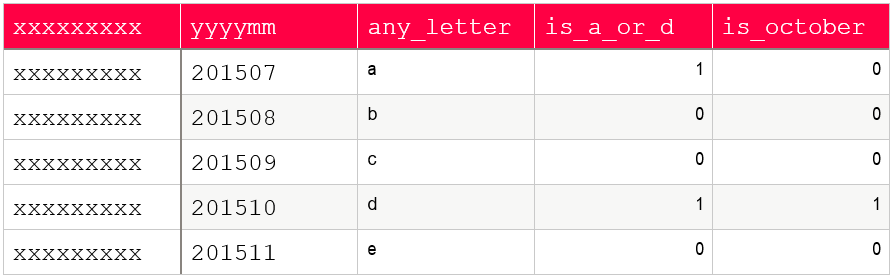
Make it configurable!
This new approach means that multiple features can be generated on a single node in a pipeline, or a single function or method in a class, without major performance losses. Thus, it is advised to create a configuration file where you can list all the feature columns to be calculated. For the two features on the example above, a configuration file in yml format might look like the following:

This type of configuration file is advantageous for several reasons:
- It simplifies the project codebase by reducing the amount of functions needed to generate feature columns to a few API-like functions.
- It creates a catalog-like, single file that can be used as the source of truth for all features calculated on the project.
- It eases the understanding of the logic and business rules applied for each new feature. You can immediately know: the name of the feature, the function that is applied, the source column and the target value.
- It is easy to maintain and expand, and no coding in PySpark is needed to create new feature columns out of existing data.
Obviously, you can use multiple functions to generate your features. Let’s inspect one of the functions on the example. The ‘isin’ function:

This post is accompanied by multiple other functions, as well as example code for parsing the configuration, creating the array-like flags, and expanding them into more traditional columns for your model training. Included for your reference, it can be adapted to suit your needs.
GitHub GIST: https://gist.github.com/sansagara/0619f21e9e56d2547e028669058644e8
Thanks to our
Author









