
Cet article décrit comment nous avons rendu explicable le modèle de prédiction de l’attrition (aussi appelé Churn) de Canal+. Auparavant, les équipes marketing de notre client pouvaient uniquement prévoir la probabilité d’attrition des abonnés, mais ne disposaient d’aucune indication leur permettant de comprendre ces futures résiliations. Désormais, elles peuvent connaître les raisons concrètes et probables d’attrition et prendre les mesures appropriées pour fidéliser les clients.
Dans cet article nous présentons comment notre équipe de Data Science a réussi à tirer réellement parti de toute la pertinence et de la richesse d’un modèle de prédiction de l’attrition utilisé depuis des années par les équipes marketing de Canal+ International. Avec l’approche déjà en place, il était uniquement possible de prévoir le risque de désabonnement d’un client au cours des six prochains mois. Cependant, ce modèle ne pouvait pas fournir les potentielles raisons ou causes expliquant pourquoi ce client risquait de cesser d’utiliser le service : en d’autres termes, il ne pouvait que générer un chiffre. Ainsi, le taux d’adoption de ce modèle par les équipes marketing internationales est resté relativement faible.
Challenges principaux
Tout d’abord, un peu de contexte, le Groupe CANAL+ est le premier groupe français de médias audiovisuels. Présent dans 40 pays, CANAL+ a pour objectif d’offrir le meilleur du divertissement à plus de 22 millions d’abonnés. L’entreprise propose des chaînes de télévision accessibles uniquement sur abonnement, ainsi que la plateforme de streaming la plus complète du marché (MyCanal) qui rassemble des films, des séries et les meilleures compétitions sportives en direct ou en replay. Elle est également connue pour son importante activité de production et de distribution de films et de séries.
Depuis quelques temps, les équipes marketing de CANAL+ International ont accès à un « score de fragilité », qui prédit la probabilité de désabonnement d’un client, mesurée sur une échelle de 0 % à 100 %. Le score généré par le modèle permet de déterminer les clients qui ont le plus de risques de résilier leur abonnement, et d’ainsi tenter de les fidéliser à l’aide d’offres commerciales spécifiques.
Malheureusement, les équipes marketing n’ont en main qu’un seul élément pour travailler : un nombre de 0 à 100. Elles n’ont aucune autre explication, aucune indication de causes possibles. Les télémarketeurs agissent à l’aveuglette, en essayant de fidéliser les clients sans arguments clairs ou pertinents.
Notre client était donc confronté à trois grands défis :
- L’incapacité d’expliquer les décisions du modèle (par exemple, pourquoi un client particulier est-il signalé comme « fragile » ?).
- Les succursales internationales étaient réticentes à l’utilisation de ce score peu intelligible, craignant en outre que le comportement du modèle ne soit trop spécifique au pays du client (c’est-à-dire trop sensible aux données d’apprentissage).
- Il y avait très peu d’indicateurs et de métriques permettant d’améliorer le modèle et de comprendre ses faiblesses.
Dans ce contexte, notre client s’était fixé trois objectifs :
- Comprendre en détail le modèle de prédiction d’attrition existant et ses prédictions.
- Améliorer grandement la pertinence et la qualité des actions des télémarketeurs, en leur fournissant des éléments concrets concernant les raisons possibles du potentiel désabonnement des clients.
- Augmenter le taux d’adoption du modèle au sein des équipes marketing internationales, en fournissant des explications claires. Ainsi, cela renforcera la confiance dans le modèle et ses prédictions.

Notre approche
Nous avons mis en œuvre notre solution de Machine Learning Intelligibility (MLI). Il s’agit d’une approche holistique dont le but est de rendre un modèle de Machine Learning (ML) explicable, interprétable et intelligible. Le projet, qui a duré 8 semaines, comprenait des évaluations de la qualité et de la pertinence des données et des modèles, l’implémentation d’indicateurs d’explicabilité et l’industrialisation du modèle expliqué, le tout en étroite collaboration avec les équipes IT et Architecture.
1. Évaluations de la qualité des données et des modèles
Une évaluation complète de la qualité des données utilisées pour entraîner le modèle, ainsi que du modèle lui-même, a été réalisée. Il s’agit d’évaluer la qualité de ces données, leur pertinence dans le contexte du modèle et ainsi d’identifier les biais potentiels (comme par exemple la géolocalisation des individus). Cette étape est cruciale pour identifier les éléments qui pourraient impacter le modèle de Machine Learning et donc biaiser les résultats obtenus.
2. Implémentation des indicateurs d’explicabilité
Une fois que les statistiques exploratoires et l’analyse détaillée des données ont été menées de manière approfondie, nous avons implémenté les indicateurs d’XAI (Explainable AI ou IA Explicable) pertinents pour le modèle à expliquer. Bien que ce modèle fasse partie de la famille des modèles Random Forests, qui possède déjà une forme d’explicabilité intégrée, il était nécessaire de déterminer quel indicateur conviendrait le mieux au contexte du cas d’utilisation.
Nous appuyant sur notre expérience de cas d’utilisation similaires, nous avons choisi d’utiliser les valeurs de Shapley pour l’explicabilité locale, et les méthodes PDP & PFI pour l’explicabilité globale. La différence entre les deux est due à la portée de l’explication : un indicateur local se concentre sur des observations individuelles (« Pourquoi la probabilité que M. Martin résilie le service est-elle si élevée ? »), tandis qu’un indicateur global se concentre sur le comportement de l’ensemble du modèle (« À quelle variable le modèle est-il le plus sensible ? »).

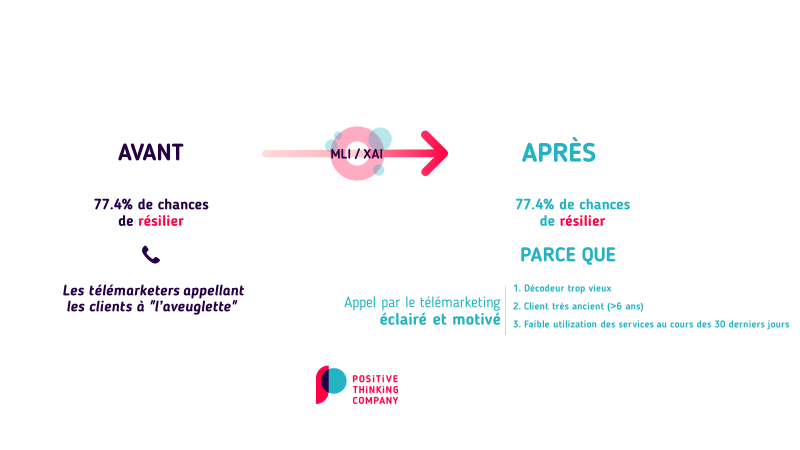
Auparavant, le modèle pouvait indiquer que le client, M. Martin, avait 77,4 % de chances de se désabonner, ce qui déclenchait une action du service de télémarketing, mais sans aucune indication ou aide concernant les raisons possibles du départ du client.
Grâce à l’implémentation de ces indicateurs, il est désormais possible de préciser les raisons potentielles expliquant la probabilité d’attrition. Dans ce cas précis, M. Martin a 77,4 % de chances de résilier parce que son décodeur est probablement trop vieux, parce qu’il s’est abonné il y a longtemps et qu’il n’a jamais bénéficié d’offres promotionnelles. Avec ces explications en main, le service de télémarketing peut présenter une offre personnalisée à ce client, par exemple en lui proposant le remplacement de son décodeur ainsi qu’une promotion spéciale récompensant sa fidélité.
3. Industrialisation du modèle expliqué
Une fois ces indicateurs implémentés, il était crucial de les mettre à disposition de toutes les équipes métier qui utilisent directement ou non le modèle d’attrition. Nous avons apporté notre support et notre assistance aux équipes DevOps / MLOps de Canal+ International afin d’industrialiser au maximum de nos développements. Nous avons notamment veillé à fournir un code entièrement conforme aux exigences techniques de l’infrastructure informatique de notre client.
Bénéfices
- Amélioration de 10 % des performances des prédictions d’attrition.
- Des leviers concrets et spécifiques utilisables par tous les différents utilisateurs finaux du modèle (comme les télémarketeurs par exemple) afin de mieux fidéliser les clients.
- Un modèle plus compréhensible et plus fiable pour les autres équipes métier.
- Une explicabilité complète du modèle, fournissant à la fois des explications globales et locales.
- Opérationnalisation des indicateurs dans le pipeline MLOps de notre client.
Aujourd’hui, notre client peut détecter qu’un client est « fragile » par exemple parce qu’il n’a pas utilisé le service pendant les 31 derniers jours, ou parce que son équipement est trop vieux.
Le modèle ayant été récemment lancé en production, les avantages en termes d’amélioration de son utilisation et de ses prédictions par les utilisateurs finaux ne sont pas encore connus. Nous vous invitons à revenir dans quelques semaines pour connaître les derniers rebondissements de ce sujet passionnant !
Équipe impliquée
Un Data Scientist et un expert en XAI ont collaboré avec notre client pendant 8 semaines sur ce projet.
Technologies

Grâce à nos
Auteur







