
Daoud Chami, Innovation Solution Manager chez Positive Thinking Company sur l’expertise Data & Analytics, se questionne sur l’évolution du métier de Data Scientist.
Cet article s’appuie sur un talk de Daoud, ‘Où va la Data Science ?’, donné à l’occasion d’un Meetup avec Lyon Data Science et lors de la Devoxx 2023.
Il s’agit d’un sujet méta, qui s’adresse au plus grand nombre, car il ne nécessite pas d’être techniquement très au fait de ce qui se fait en Data Science pour pouvoir le comprendre.
Le but est de répondre à une question, qui peut sembler facile de prime abord : Quel est l’avenir du métier de Data scientist ?
En effet, dans le contexte actuel, les clients souhaitent concevoir des produits et plus seulement des POCs, avec de plus en plus de plateformes et d’infra qui permettent de gérer toute une partie de la devOps, de la mise en production à la gestion du cycle de vie d’un modèle. D’autre part, on entend aussi beaucoup parler d’un nouveau terme : Le machine learning engineering.
Au vu de ces changements, comment les Data Scientists vont-ils devoir se positionner sur la chaîne de valeur de la Data ?
Pour répondre à cela, Daoud revient sur les bases du métier de Data Scientist, sur le périmètre des expertises des différents métiers Data et enfin sur les perspectives d’évolution de ce poste.
Qu’est-ce qui différencie les Data Scientists des autres métiers de la Data ?
Le Data Scientist est celui qui partant de données et en mobilisant des compétences métier, va, au moyen de code, entraîner un modèle. Un modèle étant un algorithme dont le comportement dépend de paramètres qui peuvent être estimés lors de la phase d’entraînement sur un grand ensemble de données et ce afin de de produire les prédictions qui soient les plus fidèles possibles aux résultats attendus. Il a essentiellement pour but de prédire quelque chose.
Le Data Scientist est soit celui qui conçoit le modèle, soit celui qui écrit le code qui produit le modèle.
Bien sûr, le Data Scientist ne fait pas que cela. Mais c’est ce qui le distingue des autres métiers liés à la Data. C’est là où résident son expertise principale et sa valeur ajoutée.
Par exemple, avec un jeu de données comprenant plusieurs variables pour décrire des biens immobiliers, la mission d’un Data Scientist peut être de prédire le prix en fonction de ces variables. Donc de répondre à la question : Est-on capable, à partir des données qui décrivent un bien, de prédire son prix ?
L’hypothèse de base est qu’il y a des corrélations qui existent entre ces variables et le prix. Le Data Scientist va alors vérifier les liens entre chaque variable et le prix de l’appartement. Mais il va aussi réaliser du feature engineering, c’est-à-dire combiner des informations pour en créer une nouvelle. Et vérifier si cette nouvelle information permet également de faire quelque chose.
Ce qui va nécessiter des connaissances métier sur le secteur concerné.
Le métier du Data Scientist est donc de collecter des informations et créer l’information quand elle n’est pas disponible, qui sera nécessaire pour faire un apprentissage, puis une prédiction.
En mobilisant des connaissances métiers et mathématiques, il peut alors proposer un modèle, qu’il faudra ensuite mettre en production.
Le Data Scientist va donc surtout mobiliser les probabilités pour prédire.
On peut déjà voir une première différence avec le métier de Data Analyst, qui à l’inverse, va mobiliser les statistiques pour décrire.
En effet, le Data Scientist va opérer essentiellement sur la chaîne suivante : Nettoyage de la donnée, extraction ou création de features pertinentes, entraînement d’un modèle, et enfin évaluation de ce dernier. Ce cycle est itératif et peut être répété autant de fois que nécessaire jusqu’à l’obtention — quand cela est possible — d’un modèle qui prédit suffisamment bien ce que l’on cherche à décrire.
Mais un Data Scientist ne fait pas que ça. Il y en a qui sont aussi plus ou moins adroits pour faire de l’analyse de données et même utiliser Tableau, Power BI, … Il y a aussi des Data Scientists plutôt bons en data ingénierie : Préparer la donnée, la mettre en forme, la stocker, de façon la plus optimisée possible sur des systèmes distribués.
Le machine learning est donc l’expertise qui les différencie, mais pas qui les caractérise. Le Data Scientist fait du machine learning, et parfois aussi de l’analyse de données et de la data ingénierie. Parfois aussi, il va déployer et même gérer la CI/CD, donc le cycle de vie d’un produit de machine learning dans un système informatique plus ou moins complexe avec tout ce que cela suppose de tests, de configuration, …
Mais cela commence à faire beaucoup ! Souvent un data scientist est polyvalent, mais c’est tout de même rare qu’il maîtrise toutes ces expertises à la fois et fasse tout lui-même.
Quels sont les périmètres du Data Scientist et des autres métiers Data ?
Nous sommes globalement passés d’une vision du métier de Data Scientist telle que représentée par le diagramme de Venn à gauche (une expertise entre mathématiques, développement et connaissances métier) à une image qui serait celle d’un couteau suisse.
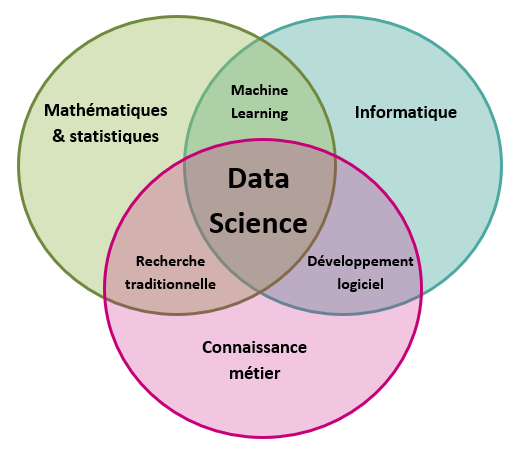
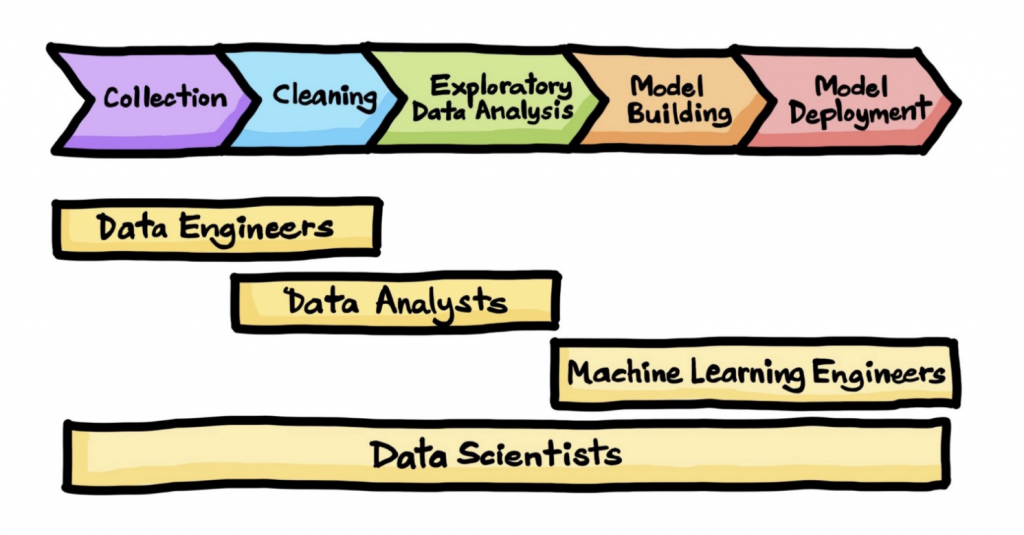
À l’origine, le Data Scientist a un cœur de métier qui est le machine learning, la modélisation et le prototypage. Ces expertises peuvent aussi être plus ou moins étendues sur l’analyse et l’ingénierie de données.
Toutefois, on peut aisément tracer une délimitation entre ce qui est plutôt de la responsabilité d’un Data Scientist, d’un Data Engineer et d’un Data Analyst. Sur une expertise donnée, il n’y a pas de doute à savoir ce qui est de la responsabilité de chacun, même si les frontières sont perméables.
Les tâches peuvent donc facilement être réparties sur un projet entre ces différents spécialistes.
En revanche la frontière côté devOps est moins nette : Déploiement, mise en production, création d’un pipeline de CI/CD, … C’est plus compliqué de dire ce qui incombe au Data Scientist et au Machine Learning Engineer (MLE). Et encore si on s’accorde sur la définition du Machine Learning Engineer. Pour certains, un MLE est un data scientist qui fait de la mise en production. Pour d’autres, il s’agit d’un devOps qui travaille dans le milieu du machine learning. Et il y en a même qui considèrent qu’il ne faut plus du tout dire Data Scientist, mais Machine Learning Engineer.
La nature des frontières entre ces deux rôles n’est pas la même. Dans un certain cas on a des frontières, certes poreuses, mais délimitées. Dans l’autre, ce n’est pas évident car on ne sait pas jusqu’où le Data Scientist doit aller et à quel moment le MLE prend le relais. D’autant plus que les métiers de Data Analyst et Data Engineer sont des métiers bien installés, et que celui de MLE est plus récent.
Après, bien qu’on ne sache pas trop où placer la frontière avec la data science, on sait qu’il y a une partie devOps qui incombe au MLE. Et c’est précisément sur cette partie devOps qu’il y a aujourd’hui la plus grosse pression. L’étape de mise en production est celle sur laquelle les projets rencontrent le plus d’écueils et qui semble aujourd’hui être la plus critique.
À titre personnel, en tant que consultant, Daoud a également pu constater que le point de réassurance des clients s’était déplacé. Il n’était plus ‘Suis-je capable de prédire ceci en fonction de cela ?’. Mais ‘Sachant que je pense que l’on peut prédire ceci en fonction de cela, comment je fais ensuite pour le déployer et comment cela va s’intégrer dans mon SI/ infra ?’.
Cela prouve que les clients sont de plus en plus matures et ont conscience du potentiel de leurs données. Mais cela correspond aussi à une inflation du périmètre du Data Scientist. Et cela contribue aussi à mettre de la tension sur les questions d’infra et de devOps.
Cette vision est aussi corrélée à un autre fait, décrit dans cet article qui parle des dettes techniques cachées dans les systèmes de machine learning. Lors du déploiement en production, il y a en effet des problématiques propres au machine learning et aux intelligences artificielles à prendre en compte. Ce qui peut porter à penser que la personne réalisant le modèle devrait avoir en tête les caractéristiques de l’environnement de production pour éviter cette dette technique.
Mais il y a un manque de maturité chez les Data Scientists sur ces problématiques-là, qui sont des problématiques à part.
Quelles perspectives pour le métier de Data Scientist ?
Comment l’arrivée de ces nouvelles problématiques et du rôle de Machine Learning Engineer peut-elle justement avoir un impact sur le rôle de Data Scientist ?
Un avis possible est que les Data Scientists vont sûrement devoir intégrer ses nouvelles compétences de MLOps. Mais finalement ce n’est peut-être pas tout à fait la réponse apportée.
Déjà comment pourrait être défini le métier de MLE ?
On peut dire qu’il s’agit d’un métier en croissance, avec une pression et un besoin assez fort.
Mais est-ce que le métier de MLE est un embranchement qui naît du métier de Data Scientist en étant un métier distinct ? Ou est-ce que MLE est le nouveau nom du métier de Data Scientist ?
Pour répondre à cette question, il faut comprendre qui sont les MLE en termes de profils.
On peut se baser sur une étude menée par LinkedIn et publiée en 2022 sur les métiers les plus en croissance entre 2017 et 2021 aux États-Unis. Le métier de Machine Learning Engineer apparaît en quatrième position. On y voit aussi les métiers d’origine des personnes qui postulent à ces annonces. Il y a majoritairement des développeurs, des Data Scientists et des spécialistes en intelligence artificielle.
Le fait qu’il y ait des Data Scientists qui forment une partie des MLE d’aujourd’hui, donne tout de même l’impression qu’on a affaire à une scission dans le métier de Data Scientists entre différents ensembles d’expertises.
On est donc tenté de penser qu’il s’agit dans la data science d’un métier qui est en train de se scinder en deux, avec une partie qui prend certaines responsabilités et une autre partie d’autres responsabilités.
Pour définir ces responsabilités, on peut revenir à ce schéma :
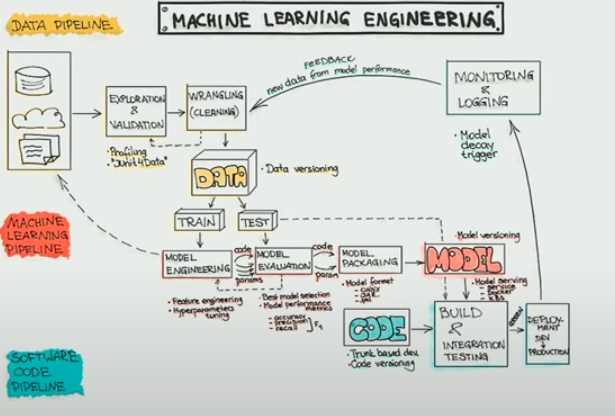
Si on ne parle que d’expertises, on voit qu’il y a une partie sur le fait de fournir des données et assurer la mise à disposition et la logistique de ces données. Le tout avec une livraison de données exploitables et accessibles. Cela pourrait correspondre au rôle du Data Engineer.
On voit qu’il y a ensuite une expertise sur la production de modèles. Et que sur cette partie machine learning, le livrable attendu est donc un modèle. Cela pourrait correspondre au rôle du Data Scientist.
Et ensuite on voit une troisième expertise qui, à partir de ce modèle, produit du code avec une partie test & build. C’est-à-dire que partant du code qui concourt à produire un modèle, on va au moyen de code applicatif faire de l’intégration et de la mise en production.
La tension sur le métier de Data Scientist vient du fait qu’on leur demande justement de plus en plus souvent de gérer cette troisième expertise. Alors que cela pourrait correspondre au rôle du MLE.
Finalement ce schéma et chaque expertise représentent assez bien là où les différents métiers vont se stabiliser. On voit ce qui sera attendu de chaque rôle et où se situe le relais entre le rôle de Data Scientist et MLE. Les métiers vont alors à nouveau se spécialiser, car on ne peut pas demander à quelqu’un de maîtriser l’ensemble de la chaîne.
Afin de confirmer davantage cette conviction, Daoud a réalisé une analyse de 80 offres d’emploi. Dont 40 offres de Data Scientist et 40 offres de MLE. Pour chaque poste, 20 offres sur Welcome to the Jungle et 20 offres sur LinkedIn ont été observées.
Pour chacun des rôles, il a été analysé le pourcentage de ces offres qui faisait mention d’une compétence en data ingénierie, en data analyse, en compréhension métier et en devOps.
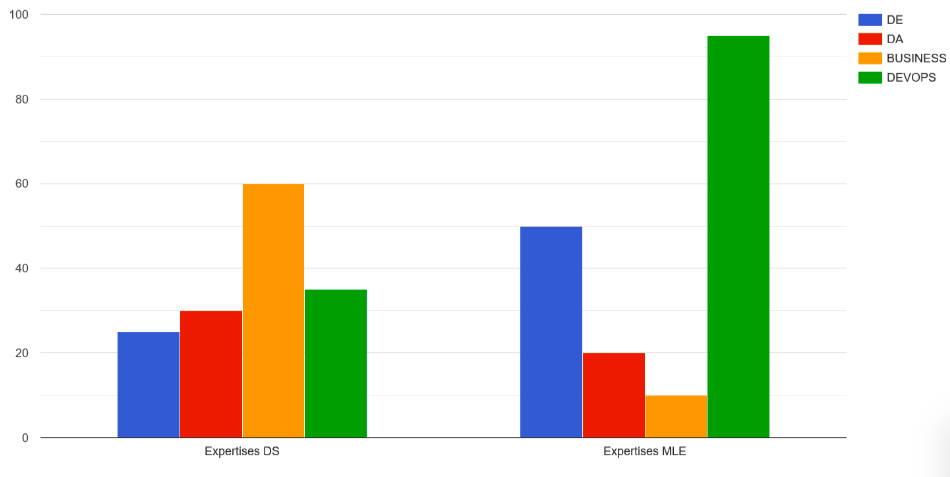
Les résultats suivants ont été obtenus :
Pour les offres de Data Scientist, la répartition des compétences recherchées est :
– Data ingénierie pour 25% des annonces,
– Data analyse pour 30% des annonces,
– Compréhension métier pour 60% des annonces . Dans la majorité des cas, on va considérer que pour un Data Scientist, il est primordial qu’il connaisse ou ait une appétence pour le secteur dans lequel il travaille.
– DevOps pour 35% des annonces,
– Et compétences en machine learning dans la totalité des annonces.
On voit qu’un Data Scientist est quelqu’un qui connaît la donnée et à qui on demande de s’intéresser au métier et d’en avoir une bonne compréhension.
Pour les offres de MLE, la répartition des compétences recherchées est :
– Data ingénierie pour 50% des annonces,
– Data analyse pour 20% des annonces,
– Compréhension métier pour 10% des annonces,
– DevOps pour 95% des annonces.
Ces résultats laissent entendre, que le MLE arrive dans une entreprise où on sait déjà prédire, ou qui est rassurée sur sa capacité à le faire, voire même a déjà un modèle existant. Le MLE est donc attendu pour mettre en production et assurer le cycle de vie du modèle.
Mais faut-il aussi avoir de vraies compétences de machine learning en tant que MLE ? Oui pour a minima pouvoir tester le modèle. Mais peut-être pas de manière très poussée. Il faut au moins être conscient de comment monitorer le modèle. Après la façon dont on va mesurer la performance du modèle dépend de la façon dont on va prédire et de ce qu’on veut prédire. C’est donc plutôt de la responsabilité du Data Scientist de définir le bon KPI. Et ensuite le monitoring peut être réalisé par le MLE.
Pour conclure, au moins dans l’esprit de ceux qui recrutent des Data Scientists et MLE, ce ne sont pas les mêmes expertises qui sont recherchées.
Les Data Scientists ont besoin de maîtriser une expertise business pour faire de la prédiction. Ils ne vont donc pas être remplacés par des MLE, de qui on n’attend pas particulièrement cette compétence.
Il s’agit de deux rôles complémentaires. On n’attend pas de chacun de savoir faire ce que fait l’autre avec une expertise en plus.
La différence n’est pas non plus une question de charge de travail, mais bien de compétences.
La distinction entre un MLE et un Devops peut aussi être fine, car cela mobilise les mêmes expertises.
Elle réside dans le fait que le MLE ne va pas versionner que du code. Il va également versionner un modèle et de la donnée. De plus, ce qui est en production n’a pas un comportement déterministe et ne se teste pas de la même façon. Il met en production quelque chose qui fonctionne aujourd’hui, mais pas forcément sur le long terme. Donc toutes ces choses-là justifient les différences entre ces deux métiers.
Enfin c’est un signe de maturité du marché que d’arriver à distinguer de plus en plus finement les différents métiers du monde de la Data.
Autour de ce sujet, vous pouvez également consulter nos articles :
Data Engineer, Data Scientist et DataOps : Des métiers et des technologies complémentaires
C’est au tour de nos experts Data de vous présenter leur discipline et leurs technologies de prédilection.blog.positivethinking.tech
Quels sont les enjeux et les usages de la Data Science en entreprise ?
À l’aide de cas concrets, Daoud, Data Scientist, présente les bases élémentaires des concepts et enjeux de la Data…blog.positivethinking.tech
Nous publions aussi régulièrement des articles sur des sujets de développement produit web et mobile, data et analytics, sécurité, cloud, hyperautomatisation et digital workplace.
Suivez-nous pour être notifié des prochains articles et réaliser votre veille professionnelle.
Retrouvez aussi nos publications et notre actualité via notre newsletter, ainsi que nos différents réseaux sociaux : LinkedIn, Twitter, Youtube, Twitch et Instagram
Vous souhaitez en savoir plus ? Consultez davantage notre site web et nos offres d’emploi.
Grâce à nos
Auteur







